
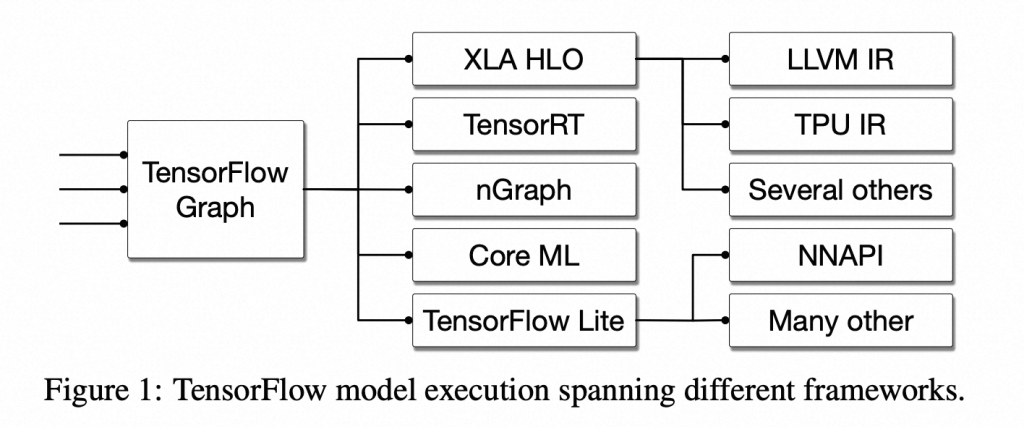
这帮大佬搞类似tensorflow 机器学习框架时,框架的底层通常由各种不同的编译器组建构成。比如上图中的图优化,各种中间compiler,和底层的各种运行时系统等等。每种组件单独解决某一类问题。
从框架整体的实现视角来看,这种零散的(由不同项目组合而成)形式是一种非常糟糕的实现😭。同时,框架的背后其实是编译器作为支撑,从编译器的实现视角来看🤗🤗:
- 这不同项目揉合而成的东东,算哪门子编译器呢!!!‼️
- 作为性能优化的底座,这框架背后各种组件各自为战,到后期一定会由于各种组件的局部最优带来项目整体的复杂度爆炸!😰
- 一个组件带来的问题,整体项目debug难度倍增,需要一个个排查是哪里出现的问题。没有一个统一的error传递手段啊这。。。🫡
- 如果有一个新的硬件出来,还得增加新的组件融合到框架里,这说明框架底座的设计实现出问题了啊。。。😈
- 对于4,正好llvm project解决过这个问题,通过抽象一层中间表示LLVMIR,统一了各自为战的轮子,有了整体的全局的优化。那我们这机器学习框架,现在面临的问题不就是当时llvm 项目面临的问题,几乎一摸一样的么!
所以,这帮以前搞llvm的大佬,面对工业界新的问题,开始了造轮子新征程。但是他们的这个动机是那么让人信服,那么的让人佩服,更关键的是他们就是搞llvm的啊,mlir进llvm岂不是顺理成章。。。
大型开源项目维护者和开创者的作用和影响力这就出来了,新轮子只要动机纯净干脆,解决痛点,很容器获得业界广泛拥护。。。。
ps: 编译器这种需求小众(没几家公司玩),而带来的就业面狭窄,业务通用性过低,抗风险能力差的岗位,如今也如雨后春笋般冒头。。。如果芯片热和国产替代过了这段时期,不知以后从业者路向何方?强行转行其他方向的性能优化?不知后事如何。
Comments NOTHING